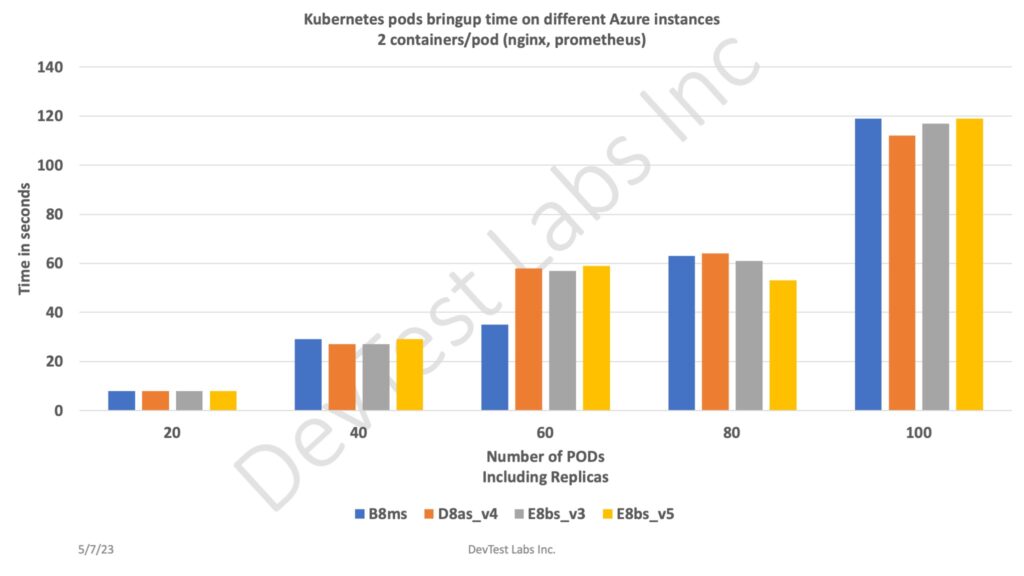
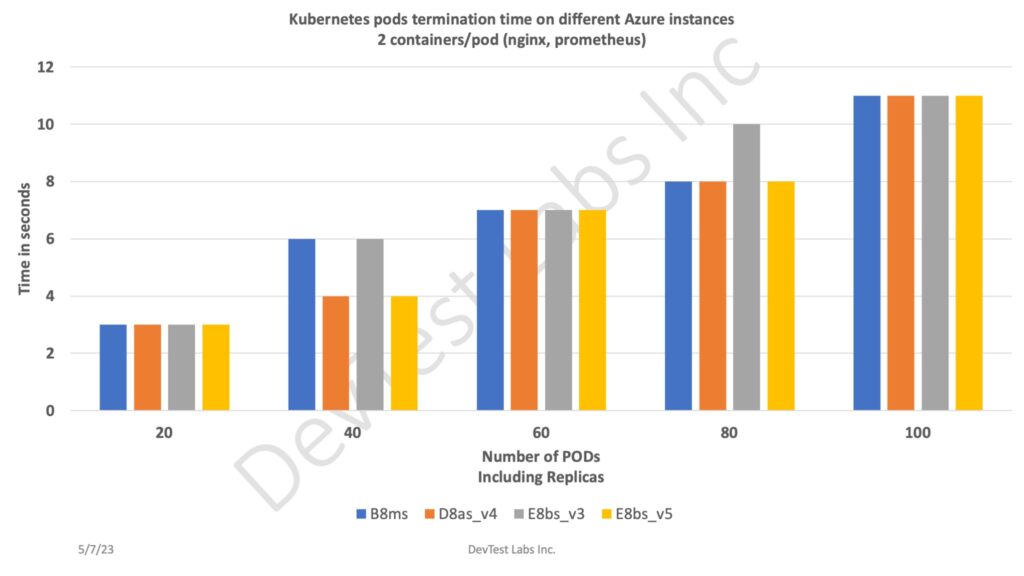
- We have a specific need to frequently bring up and terminate k8s pods. For this purpose, we did some experiment with few Azure instances with below requirements:
- 8 vCPUs
- 32gb or more
- premium SSD
- Use one master node (D8s_v4) and one worker node (test instances) for every test
- Other k8s configurations
- Metrics pod
- Calico CNI plugin
- CRI-O container runtime
- POD configuration
- 2 containers per pod (nginx, promotheus)
- 2 replicas per pod
- Goal is not to try deployment on bigger scale, instead we want to check how vCPUs from different instance types perform at small scale for same type of k8s pods bring up and terminate
- Goal is to identify cheaper instance(s) when we want to run in much bigger scale
- No workload runs on containers
- Test instances (US East region)
- B8ms
- F8s_v2
- E8bs_v5
- D8s_v4
- We ran each test 3 times and picked lowest time (best) out of 3 for each set of pods
- Our observation after all runs
- Surprisingly on lower cost instance (B8ms), pods bringup and terminate time is pretty much on par with higher cost instances. We expected some reasonable improvements in bring up/terminate time with high end instances.
- That being said that, running workload might change this behavior.
- If you are interested, use with caution as ballpark numbers. It might vary depending on multiple factors (current cloud usage in that zone, physical backing store used, instance type used, etc). These are the numbers we got in our run. We are not liable for any loss or damages caused by using this data.